Transformerを振り返る:2017年の原論文から2026年の現在地まで
目次
AIの世界を変えた数式だ。(一見難解に見えるが、第2章を読み終える頃にはその仕組みがわかる。コンテキストに基づいてすべてのトークンが自分自身の意味を更新する、非常に巧妙な計算だ。)
2017年、Googleチームによって初めて提案された1。BERTなどのモデルを通じて研究コミュニティへ広まり、OpenAIのChatGPTが世界へ届けた「Scaled Dot-Product Attention」の数式だ。2026年現在、ChatGPT・Gemini・Claudeの「ビッグスリー」LLMは、生成するすべてのトークンに対してこの計算を繰り返している。DeepSeek、MoonshotのKimiモデル、Zhipu AIのGLMといったオープンソースモデルも同様だ。
この記事では、次の2点をわかりやすく解説する。
- 2017年に提案されたTransformerアーキテクチャとは何か。
- この9年間で何が変わったのか。
第1章 — Transformerの誕生
Transformer以前、NLP(自然言語処理)研究はRNN(Recurrent Neural Networks)が支配していた。RNNとTransformerはどちらも人工ニューラルネットワーク(ANN:Artificial Neural Network)を土台とした仕組みだが、設計思想はまったく異なる。GRUとLSTMが主役であり、これらはRNNの「勾配消失問題」への回答として生まれた。勾配消失問題とは、長いシーケンスの先頭にある情報をネットワークが記憶できなくなる現象だ。
深掘り ▸
通常の人工ニューラルネットワークにおいて「深さ」とは、層を増やすことを意味する(建物の階を増やすようなものだ)。RNNでは「深さ」は文章の長さになる。500単語のテキストがあれば、RNNは500の「仮想的な」層を通じて信号を伝播させなければならない。重みを更新するために文の冒頭まで計算が届く頃には、信号はほぼゼロになっている。これが「勾配消失」だ。「長いシーケンスの先頭の情報を記憶できなくなる」という説明は、原因ではなく症状を述べているだけだ。
それでも、GRUとLSTMは軽減策に過ぎない。入力が非常に長くなれば同じ問題に直面する。さらに根本的な問題があった:ハードウェア効率の悪さだ。これを理解するには、まずこれらのモデルを動かすハードウェアを知る必要がある。
CPUとGPU:専門家たちと工場の作業員たち
CPUは少数の専門家のチームだと考えてほしい。投げかけられたあらゆるタスクをこなすことができる。GPUは数万人の作業員を擁する工場だ。個々の作業員に特段の賢さはないが、数で圧倒する。
タスクが最先端のスーパーモト向けラリーバイクの製造だとしよう。専門家には、過去データの分析、テレメトリの解釈、エンジンのカスタマイズ、実験と部品の微調整などが求められる。作業は高度に複雑で、順序通りに進める必要がある。
では、ドライブチェーンの金属リンクを1つずつ製造するような、単純だが大量のタスクはどうだろうか。1万人の作業員に金鎚と金属素材を渡せば、全員が同時に打ちつけられる。専門家がエンジンを1つ調整する時間で、1万個の完成したリンクが手に入る。
ここが核心だ。人工ニューラルネットワークの学習は、鎖のリンクを金鎚で打つのと同じくらい、実は非常に単純な作業の繰り返しなのだ。研究者たちは、この膨大な計算を「行列演算」という形にまとめた。「行列」と聞くと難しく見えるが、単に数字がぎっしり詰まった巨大なExcelのスプレッドシートを想像してほしい。
GPUの1万人の作業員にそれぞれのセルを割り当てれば、全員が一斉に金鎚を振り下ろし、一瞬でシート全体を計算し終えることができる。競争の軸は「賢さ」から「並列効率」へと移行した。
RNNの失敗:組み立てライン
RNNは厳格な工場の組み立てラインのように系列を処理する。現在のステップは、直前のステップが完了して結果を渡すまで開始できない。つまり、シフト1が終わって部品が流れてくるまで、シフト2の作業員は手を動かせないのだ。
1,000単語の文書であれば、工場は1,000回の順次「シフト」をこなさなければならない。1単語につき1シフト、前が終わるまで次は始められない。1単語目の処理に1秒かかるなら、1,000単語の処理が完了するまでに合計1,000秒かかる。作業員を増やして高速化する方法はない。1,000番目の作業員は999番目の出力を待ち続けているからだ。工場は「次のステップ」依存性に縛られて動けなくなる。GRUとLSTMもこれを解消しない。設計上、順次処理のままだ。
さらに情報の問題もある。RNNが1,000単語の文書を読む場合、各ステップで読んだ内容を1枚の付箋にまとめ、更新し続けなければならない。1,000単語目に達する頃には、1語目の情報は999回の上書きで消えている。Transformerはこの2つの問題を解決し、NLP研究を革命的に変えた。
Transformer:オープンフロアプラン
Transformerはこの制約を完全に取り除いた。新しいトークンを生成する際を除いて。RNNの「再帰」部分を廃棄し、系列は「attention」機構だけで処理できると主張した。
組み立てラインの代わりとして、Transformerはすべての単語(位置番号付き)を工場のフロアへ一度に並べる。1,000人の作業員全員に「文書全体を一度に見て、すべての単語の関係を一度に把握せよ」と指示する。作業員(パラメータ)を増やすほど品質が予測可能に向上するため、スケーリング則が意味を持つようになった。Transformerが「勝った」のはここが理由だ。LLMが爆発的に普及した主な原因でもある。
注:推論時(テキスト生成時)、トークンの生成はまだ逐次的だ。なぜそうなるかは第2章2.4節で、その対処法は第3章3.4節で扱う。
深掘り ▸
Transformerより前に「attention」は存在したのか?実は存在した!ただし、まったく異なる形で。
このメカニズムは今日「cross-attention」と呼ばれ、エンコーダとデコーダの間のボトルネックを解消するために存在していた。入力系列全体を単一の固定長ベクトルへ圧縮するのではなく、デコーダは新しい単語を生成するたびにエンコーダのすべての隠れ状態を「振り返り」、重み付きの和(コンテキストベクトル)を計算できた。
これはTransformerのSelf-Attentionとは異なる。興味深いことに、2017年のTransformer自身もこのエンコーダ・デコーダのcross-attentionを使用している——数式は同じだが、入力が異なる。
第2章 — Transformerの仕組み
チャレンジ: 本章に入る前に、図をよく見てほしい。ボトルネックになりそうな箇所はどこだろうか?メモしておこう!2026年の研究者たちが、あなたが見つけたのと同じ問題を解決したかどうか、後で確認してみよう。 そこに、新たな研究の可能性が潜んでいる!
2.1 入力パイプライン:データの準備
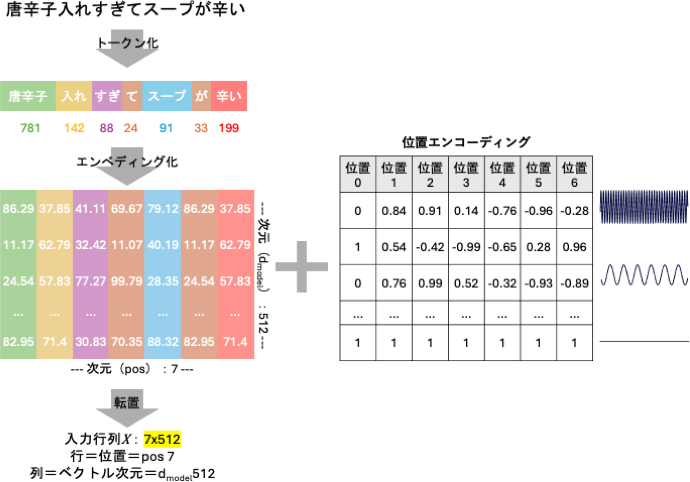
人工ニューラルネットワークは整数や浮動小数点数などの数値しか扱えない。入力パイプラインは、人間の言語をニューラルネットが処理できる行列演算に変換する。
トークン化
モデルは文を「トークン」と呼ばれる扱いやすいかたまりに分割する。単語や文字の場合もあるが、通常はサブワードだ(例:「味噌ラーメンが好き」は「味噌」「ラーメン」「が」「好き」になる)。
深掘り ▸
これは、LLMが「strawberryに含まれるRの数は?」というテストで失敗してきた歴史的な理由でもある。今日でもChatGPTの失敗例はある。段落を与えて特定の文字の出現回数を尋ねるなど、より長いプロンプトが必要な場合もある。ツールを使えるLLMは、このカウントを省略して直接Pythonスクリプトを書いて実行する場合もある。
各トークンは固定辞書からID番号(整数、例:ID 4092)にマッピングされる。
エンベディング
ID番号は恣意的で、本質的な意味を持たない。「意味」を付加するために、モデルは各トークンIDを高次元ベクトル(数値のリスト、通常512次元以上)に変換する。
これは、トークンを巨大な3D(実際には512次元以上!)マップ上にプロットするようなものだと考えてほしい。理想的には、似た意味を持つトークン(「りんご」と「果実」など)は、この座標空間上で互いに近い位置に配置される。
逆に、「りんご」と「店」のように意味が異なる場合は、このマップ上で遠く離れた位置に配置される。注意点:エンベディングは意味の「出発点」に過ぎない。次節で説明するAttention機構が、文脈に応じてこの意味をさらに動的に更新する。
深掘り ▸
トークン化=サブワードをIDにマッピング、エンベディング=IDを「意味」にマッピング、という関係から、エンベディングはトークン化の手法と密接に結びついていることがわかる。
位置エンコーディング
Transformerは「オープンフロアプラン」ですべてを一度に処理するため、系列の順序を本質的に認識できない。「社長が部下を評価する」と「部下が社長を評価する」は、作業員には同じに見える。
これを解消するために、波のような数学的信号(波形パターン)を各トークンのエンベディングに注入する。この情報はタイムスタンプや位置番号として機能する。
エンベディング1には特定の波形パターンが加算され、エンベディング2にはわずかにずれた波形パターンが加算される。ネットワークはこれらのパターンを読み取り、順序を復元することを学習する。
2.2 スケールドドット積アテンション:Q・K・V
これがTransformerアーキテクチャのコアエンジンだ。名前は威圧的に見えるが、実際には数式の各部分を説明しているに過ぎない。イントロの数式を思い出してほしい。
「scaled」はの部分、「dot-product」はの部分だ(softmax()もスコアを正規化するという意味でスケーリングの一部と言える)。
Vとの乗算が「attention」部分だ。それでも怖く見えるなら、「すべてのトークンがコンテキストに基づいて自分自身の意味を更新する」というヒントを思い出してほしい。
Transformerは、すべてのトークンに対して3つのベクトルを使ってattentionを計算する。いずれもトークンのエンベディングベクトルから導かれる:Query(Q)、Key(K)、Value(V)だ。
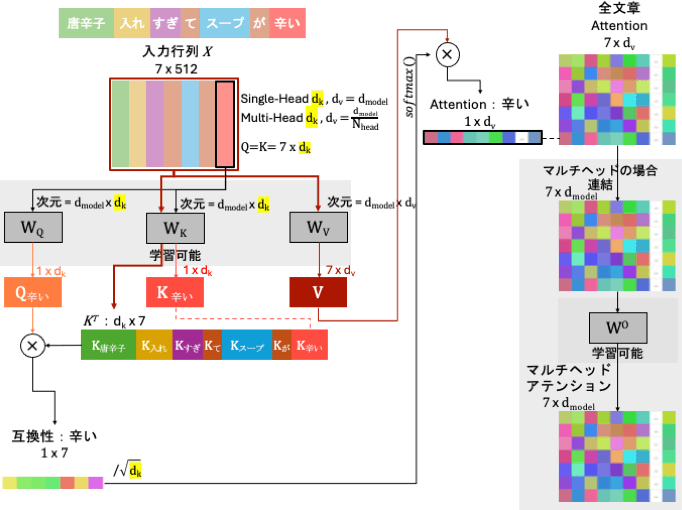
これは効率的なネットワーキングイベントだと考えてほしい。
Query(Q)「自分が探しているもの」: 現在のトークンが必要なコンテキストについて質問する(例:トークン「辛い」が「周囲に食べ物関連または感情関連のトークンはあるか?」と尋ねる)。
Key(K)「自分が何者か」: すべてのトークンが自分のアイデンティティを発信する(例:トークン「スープ」が「私はスープです」と発信する)。
Value(V)「自分が本当に意味するもの」: 最終結果に混ぜ込まれる、トークンの根底にある内容や実体だ。
数式がこの「混合」をどのように実行するかを見ていこう。
ドット積「互換性テスト」(): モデルは現在のトークンのQueryを取り、文中のすべてのトークンのKeyと照らし合わせる(ドット積計算)。これは、自分が求める条件の「チェックリスト」と、相手のプロフィールを突き合わせるようなものだ。
条件がピタリと一致するほど大きな正の数になり、マッチしないほど小さな数(または負の数)になる。(※数式のTは、計算の形を合わせるためにグリッドを横に倒す「転置」を意味する)
スケーリング(で割る): ベクトルが非常に大きい場合、ドット積の数値は爆発する可能性がある。ベクトルの次元数の平方根で割ることで、計算を安定させる。
スコアをパーセンテージに変換(softmax): 生の互換性スコアはsoftmax関数を通過する。これにより、すべてのスコアが正になり、合計がちょうど1.0(100%)になる。例えば「辛い」は、「スープ」(70%)・「唐辛子」(20%)・自身(10%)の順でattentionを向ける。
意味の混合(V): 最後に、モデルはそれらのパーセンテージを各トークンのValue(V)と掛け合わせ、すべてを合算する。
深掘り ▸
実はQ・K・Vは直接学習するパラメータではない。3つの別個の学習可能な重み行列(・・)をトークンのエンベディングに掛け合わせることで生成される。
「Qは自分が探しているもの」「Kは自分が何者か」という意味を持つという数学的な保証は存在しない。ネットワークは、このように情報を整理することが誤差を最小化すると学習するだけだ。QとKが同じ行列へ収束しないのは、それぞれがまったく別個のランダム初期化済み重み行列を乗じることで生成されるからだ。さらに、学習プロセスが自然に両者を異なる役割へと形成する。これが、$QK^T$の対角成分が最大値になるとは限らない理由でもある。
出力は、「辛い」トークンの更新されたベクトルで、今では「スープ」の数学的な「風味」の70%を含んでいる。トークンはコンテキストに基づいて自分自身の意味の更新に成功した。この部分は「attentionブロック」または「attention層」と一般的に呼ばれ、ここでは「Single Head Attention(SHA)」として説明してきた。
なぜ「Single Head」なのか?この話ではQKVのセットが1つだけだからだ。そして、「Multi-Head Attention(MHA)」も存在する。1人で本を読むのがSHAであれば、MHA(ヘッド数=8の場合)は8人の異なる読者を雇うようなものだ。読者1は感情的な含意のみを探し、読者2は文法構造のみを探し、読者3は地名を探す。全員が同じテキストを並行して読み、それぞれのQ・K・Vを計算し、最後にノートを統合する。
ただし、8人分のノートをそのまま繋ぎ合わせるとデータが大きくなりすぎるため、2017年の著者たちは最後に別の学習可能な重みを掛け合わせて、元のサイズに圧縮・ブレンドすることを提案した。実際には、この最後の学習可能な重み(変換行列)は、サイズ調整などのためにSHA・MHAどちらにも常に存在する。
2.3 残りのブロック
Self-Attentionはtransformerブロックの一部に過ぎない。トークンが情報を交換した後、次の層へ移る前にいくつかのメカニズムを通過する。
Feed-Forward Network(FFN): 最もよく使われる人工ニューラルネットワークブロックだ。TransformerではこのFFNブロックで、各トークンが新しい「attention」情報を個別に処理する。各トークンの更新されたベクトルに対して独立して適用される、標準的な全結合人工ニューラルネットワーク層だ。
残差接続(Residual Connections): 深いネットワークでは、多くの層を通過するうちに元の情報は失われやすい。簡単に言えば迂回路だ。元のエンベディングをAttention層の出力に直接加算する。これにより、コンテキストを分析しながらも、モデルが元の意味(エンベディング)を「忘れる」ことを防ぐ。
Layer Normalization: ベクトルを繰り返し加算すると数値が制御不能なほど大きくなり、学習プロセスが不安定になることがある。Layer Normはすべての主要な演算(AttentionとFFN)の後に、数値を安定したベースラインに再センタリングおよびスケーリングする。第3章では、残差接続の前に正規化を行う(Pre-Norm・RMSNorm・2026年の標準)場合と後に行う(2017年の方式)場合の違いも見ていく。
2.4 出力と学習
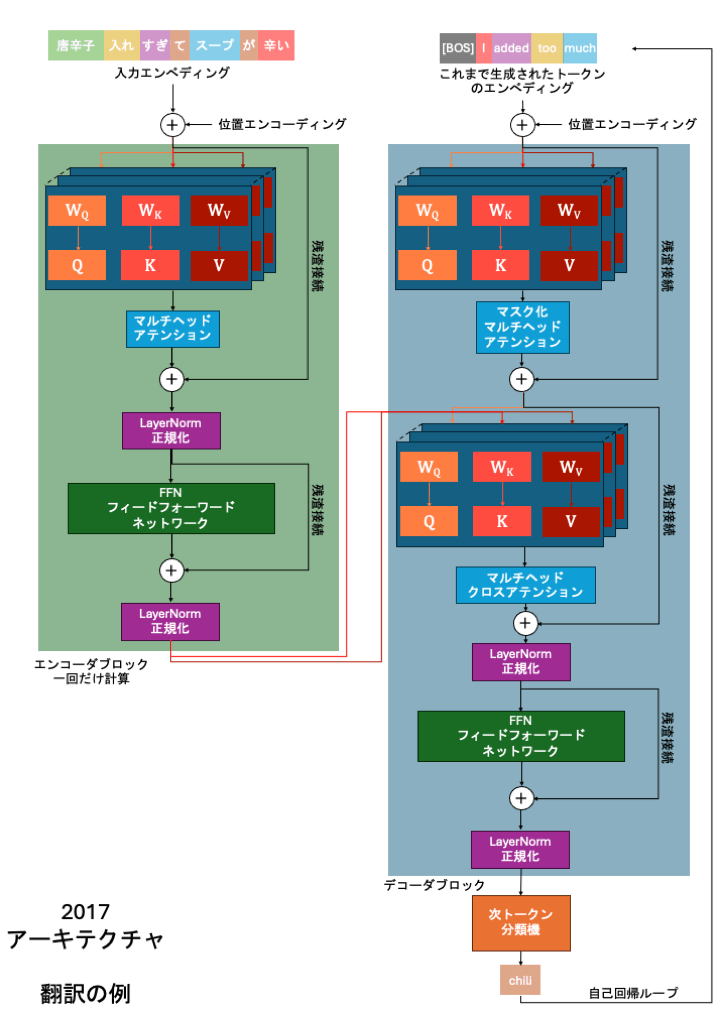
Teacher Forcing:「オープンフロアプラン」でTransformerを学習させる手法だ。テキスト生成と同じ方法でモデルを学習させると(2単語目を予測して待ち、3単語目を予測して待つ)、第1章で述べた並列効率が失われる。代わりに「Teacher Forcing」を用いる。正解の系列全体を一度にモデルへ与える(例:「唐辛子入れすぎてスープが辛い」)。モデルは、1単語目から2単語目を予測する練習、1〜2単語目から3単語目を予測する練習、1〜3単語目から4単語目を予測する練習を、単一の大規模な計算ステップで同時に行う。
Masked Self-Attention(目隠し): 学習時、Transformerの目標は系列の次のトークンを予測することだ。しかし、オープンフロアプランですべての単語を一度に並べているため、「カンニング(まだ見えてはいけない未来の単語を覗き見して、現在のクイズに答えること)」を防ぐ必要がある。これを解消するため、Self-Attentionステップで「マスク(目隠し)」を適用する。現在のトークンのQueryが未来のトークンのKeyを参照できないよう、互換性スコア(ドット積の結果)を強制的にマイナス無限大にする。softmax関数を通過すると、マイナス無限大はちょうど0%になる。これにより、トークンは未来の情報に0%のattentionを与え、過去のパターンのみに基づいて学習するよう強制される。
深掘り ▸
2017年のオリジナルのTransformerアーキテクチャは、2つの独立したブロックで構成されていた。
「エンコーダ」: 入力系列を読む。通常のSelf-Attention(マスクなし)を使用するため、すべてのトークンが前後の文脈全体を参照できる。
「デコーダ」: 出力系列を生成する。先を見越せないよう、Masked Self-Attentionを使用する。
実際には、2017年のTransformerは両者を橋渡しするために第3のメカニズムも使用していた:Cross-Attentionだ。Cross-Attentionではベクトルが分割される。Queryはデコーダ側から(「次に生成すべき概念は何か?」)、KeyとValueはエンコーダ側から(「元の入力文のコンテキストはここだ」)来る。
ChatGPT・Gemini・ClaudeなどのモダンなLLMは異なる。デコーダのみのアーキテクチャだ。エンコーダ半分とCross-Attentionメカニズムを完全に捨てた。なぜなら、生成AIが「系列Aを系列Bに翻訳する」から「1つの連続した系列で次のトークンを予測する」へとシフトしたからだ。2026年では、デコーダのcausalマスキングがモデル内のすべてのブロックに適用され、プロンプトは単に系列の冒頭になる。
この大規模な並列効率を使ってモデルを学習した後、推論(ユーザーに新しいテキストを生成する)のために実際の運用に移す。しかし、ユーザーはまだ「未来の」テキストを書いていないため、モデルは逐次的に1トークンずつ回答を生成せざるを得ない。この自己回帰的な現実が、大規模な速度とメモリのボトルネックを生み出した。これらのボトルネックを解決することが、その後9年間の研究を牽引した。
第3章 — 9年間の進化の軌跡:6つのブレイクスルー
2017年のTransformerは、並列処理という「工場フロア」での学習において革命的だった。しかし、それはあくまで翻訳タスクのために作られたものであり、ChatGPTのようにAIが自由に長文を書き続けるテキスト生成を想定したものではなかった。
自己回帰の罠: 新しいテキストを生成(推論)する際、モデルは前の単語から次の単語を予測するため、どうしても1トークンずつ出力せざるを得ない。これは、せっかくの「工場の並列処理」という最大の強みを完全に崩してしまう。その後の9年間の研究は、この逐次的なトークン生成が引き起こす「安定性」「メモリ」「速度」のボトルネックを解消することに費やされた。
なお、以下に述べる「現在の標準」は2026年4月時点のものだ。技術の多くは2024〜2025年に提案されており、LLM研究は業界の標準化を上回るスピードで進化し続けている。
本章では、この9年間で起きた進化を6つのステップ(軌跡)に分けて解説する。
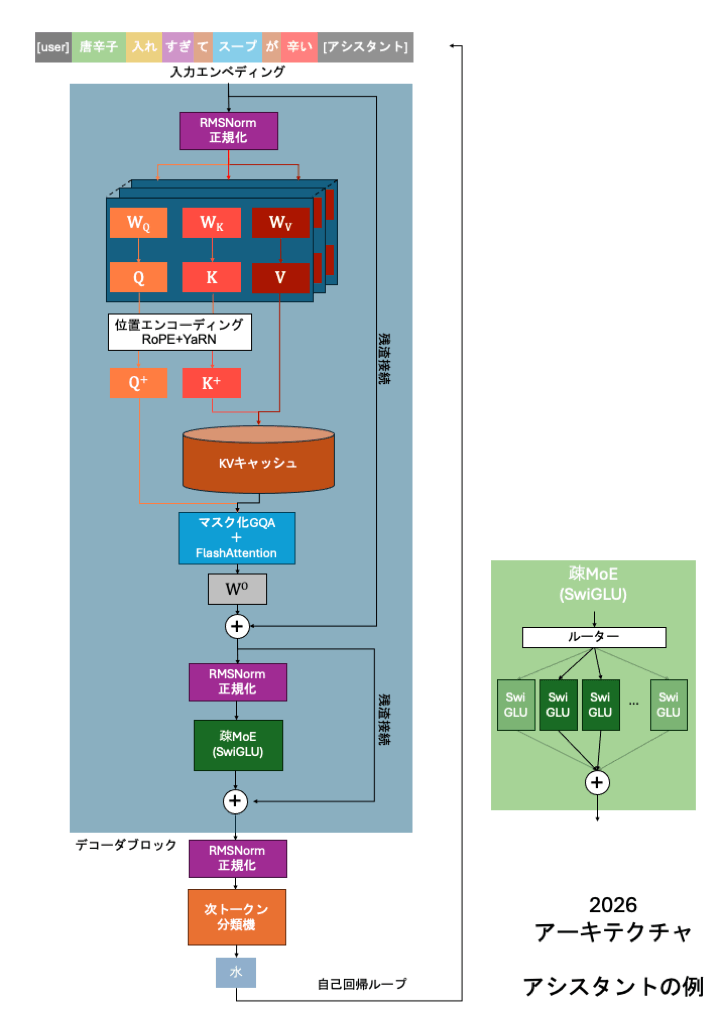
3.1 安定性:Pre-NormとRMSNorm
2017年の方式(Post-Norm): オリジナルのアーキテクチャは、AttentionブロックとFFNブロックの後にLayer Normを適用していた。この方式の弱点は、モデルの階層が深まるほど明らかになった。ネットワークを伝わる計算の数値が制御不能なほど巨大化したり、逆にゼロへ消えたりして、学習プロセスが崩壊してしまうのだ。
2026年の標準(Pre-NormとRMSNorm): 正規化はブロックの前に行われるように変更された(Pre-Norm)2。これにより深いネットワークが安定する。さらに、標準的なLayerNormの計算効率の悪さも判明した。LayerNormは平均(データをゼロにシフト)と分散(スケーリング)の両方を計算する。現代の標準であるRMSNormは、平均のセンタリングを省略し、Root Mean Squareによるスケーリングのみを行う3。7〜64%高速でありながら、同等の安定性を維持する。
3.2 位置エンコーディング:絶対位置から相対位置へ(RoPEとYaRN)
2017年の方式(波形パターン): 元の論文は、エンベディングに注入された絶対的な波形パターンを使用していた。著者たちはこれらの連続的な波形により、モデルが未見の学習したことのない長さの文章にも適応できると期待していた。しかし実際には、長い文書では計算の精度が著しく劣化してしまった。
2026年の標準(RoPE): エンベディングに位置番号を加算する代わりに、RoPEはQ・Kベクトルを多次元空間で位置に紐づいた角度だけ数学的に回転させる。ドット積を計算すると絶対的な回転が打ち消され、数学的な出力が自然に2つのトークンの相対的な距離になる。この厳密な相対マッピングにより、モダンなLLMは100万トークンを超えるコンテキストウィンドウでも整合性を維持できる4。
YaRN拡張: RoPEをさらに改善するため、現在の標準はYaRN(Yet another RoPE extensioN)を組み込んでいる5。YaRNは数学的な回転スケールを動的に伸縮させ、完全な再学習サイクルを必要とせずにモデルが長い文脈長を扱えるようにする。
3.3 FFNの強化:SwiGLUとバイアスの削除
2017年の方式(ReLUとバイアス): FFNは「ReLU」と呼ばれる計算ルールを使用していた。これはマイナスの数値を強制的に「ゼロ」に切り捨てる仕組みだ。弱点は、計算が一度ゼロになると、その情報の経路が完全に停止してしまう「死んだ回路」問題が起きることだ。また、2017年のモデルは計算結果を微調整するために「バイアス(基準値の底上げ:y = mx + bの +bの部分)」を使用していた。
2026年の標準(SwiGLUとNo-Bias): 現在の標準であるSwiGLUは、小さなマイナスの値に対しても「調光スイッチ」のように少しだけ電気を通す滑らかなカーブを採用している。さらに「ゲート(門)」の仕組みを組み合わせることで、データを2つのルートに分けて掛け合わせ、モデルが自分自身のロジックを動的に評価し、不要な情報をフィルタリングできるようになった 6。
バイアスについては、モダンなモデルは線形層のこの「+ b」を省略するのが標準になった7。バイアスを排除することでメモリが節約され、計算が純粋な行列乗算(巨大なExcelの掛け算)のみに簡略化される。大規模モデルでは、学習の安定性向上も確認されている。
3.4 記憶のボトルネック:KVキャッシュとGQA
推論の問題: 100番目の単語を生成する際、モデルは過去の1〜99番目の単語と条件を照らし合わせなければならない。1単語進むたびに、過去の99個の単語のKey(K)とValue(V)をゼロから計算し直すのは、計算上の大きな無駄だ。
基本的な解決策(KV Cache): GPUは、一度計算した過去の単語のKとVのデータをメモリに保存(キャッシュ)しておく。新しい単語のQは、この保存された過去のK/Vとだけ掛け算を行えば済む。
マルチヘッドの罠: 第2章で触れたように、モデルが64人の「読者(Attentionヘッド)」を雇っている場合、1つの単語につき64セット分のKとVを保存しなければならない。読み込む文章が長くなると、このKVキャッシュがGPUのメモリ(VRAM)容量を物理的にパンクさせてしまう。つまり、モデルは「頭の良さ(計算力)」ではなく「記憶スペースの不足」で限界を迎えるのだ。
2026年の標準(GQA): 初期の案はMQA(Multi-Query Attention)だった。全読者(Q)にK/Vメモを1つだけ強制共有させる手法だが、文章の品質を落としてしまった8。そこで、GQA(Grouped Query Attention)が最適な中間解として採用された9。全員に個別のメモを持たせるのではなく、読者をグループ化する手法だ。例えば、8人の読者(Q)のグループで1つのKと1つのVを共有する。これにより、回答の賢さをほとんど落とさずに、KVキャッシュのデータサイズを1/8に圧縮できる。
3.5 速度のボトルネック:FlashAttention
2017年の欠点: 標準的なAttentionは、単語数×単語数(N×N)の巨大な照合表を作り出す。1万単語の入力文(プロンプト)なら、1億マスもの「互換性チェック表」が必要になる。計算自体はGPUが一瞬で終わらせるが、その巨大な表の「保存」が問題を引き起こす。
ハードウェアの現実: GPUの内部には、巨大だが低速な「倉庫メモリ(HBM)」と、極小でも超高速な「作業台メモリ(SRAM)」の2種類がある。従来のAttentionでは、GPUはまず作業台で計算した巨大な表を、わざわざ遠くて遅い倉庫まで保存しに行く。次の計算のためにまた倉庫から取り出し、計算後はまた倉庫へ戻す。この無駄なデータの往復を繰り返していた。
2026年の標準(FlashAttention): FlashAttentionは、このハードウェアの構造に合わせて計算手順を賢く書き直した手法だ。巨大な計算を小さな「タイル(ブロック)」ごとに分割する。照合テスト、パーセンテージ変換、意味の混合といった一連の作業を、すべて超高速な「作業台」の上だけで一気に完結させ、最終的な計算結果だけを「倉庫」へ送る。巨大な途中経過の表を倉庫に一度も書き出さないことで、劇的な高速化を実現した10。
3.6 疎な計算:MoEと中国LLM
2017年の方式(Dense): 700億パラメータのモデルは、すべてのトークンを処理するために700億パラメータすべてを使用する。2,000億パラメータへのスケールアップはモデルを賢くするが、計算コストが高くなりすぎて、実際の運用が困難になる。
2026年の標準(MoE): MoEは巨大なFFNブロックを「エキスパート(専門家)」と呼ばれる小さな独立したサブネットワークに分割する11。ルーター: 小さな振り分け役(ルーター)が単語を分析し、最も関連性の高い専門家にのみ送る(例:8人のうち2人だけを使う)。トレードオフ: Mixtral 8x22Bなどのモデルは総パラメータ数が約1,400億に達するが、1単語あたりの計算は約390億パラメータのみだ12。つまり、150億パラメータのモデルと同じ速さでサクサク動く。ただし、1,000億パラメータすべてがGPUのメモリに常駐している必要があり、計算コストは低いにもかかわらず大規模なメモリ容量が求められる。
DeepSeek・Kimi・GLMをはじめとする中国のLLMは、2024〜2025年にかけてこのアーキテクチャを積極的に採用した。各モデルの詳細はSebastian Raschkaのアーキテクチャギャラリー13を参照してほしい。
おわりに — Transformerを教育する
これら6つのステップを終えた時点で、2026年のモダンなTransformerは工学の傑作だ。無限に拡張可能なコンテキストウィンドウ(RoPE)、高度に圧縮されたメモリ消費量(GQA)を備えている。超高速な作業台での計算(FlashAttention)、そして計算コストのわずかな部分で動作する巨大な「脳」(MoE)も搭載している。
しかし、最後の落とし穴がある。この段階で、モデルは本質的に「非常に博識な宇宙人のオウム」だ。
これを「Base Model」と呼ぶ。その唯一の目的は、インターネットデータに基づいて次の論理的なトークンを予測することだ。Base Modelに「鍵のピッキングの方法は?」と問いかけても、指示は返ってこない場合がある。代わりに、小説執筆フォーラムの学習データから「第2章:泥棒はドアに近づいた。」という文章を次のトークンとして出力するだろう。この統計的なオウムをChatGPTやClaudeのような役立つアシスタントに変えるには、アライメントが必要だ。
RLHF(ChatGPT, 2022年): Reinforcement Learning from Human Feedbackは、ChatGPTを生んだブレークスルーだ。提案自体は2017年だが、2022年に広く普及した。研究者たちは人間に常にAIの回答を評価させた(高評価/低評価)。このデータを使って「報酬モデル」を学習させた。採点基準を持った厳しい教師のようなもので、役立つ回答には報酬を与え、有害または役に立たない回答にはペナルティを与える。
DPO(2023年〜): 2026年には、業界の多くがDirect Preference Optimizationに移行した。研究者たちは、人間の好みを別の報酬モデルを介さずに直接モデルの重みへ数学的にマッピングする方法を見つけた。
アライメントはモデルをより賢くするわけではない。宇宙人が膨大な知識を人間にとって有用な形式でフォーマットする方法を教えるだけだ。
では、2017年の「Attention Is All You Need」論文を振り返ってみよう。2017年と2026年を比較したとき、何が残っているか?
コアの数式だ。鼓動する心臓だ。9年間の怒涛の数兆ドル規模のAI研究においても、この単一の数学的概念は根本的に変わっていない。2026年のすべての主要なLLMの内部で、まったく同じ「ネットワーキングイベント」を実行し続けている。
変わったのは、テキストを1単語ずつ生成すること(自己回帰)がハードウェアにとって残酷なほど非効率なプロセスだという認識だ。2017年から2026年への進化は、単語が互いに関連性を計算するための「より良い数式」を発見することではなかった。GPUの工場作業員を速く動かし、作業台のメモリを節約し、組み立てラインを止めることなく脳を数兆パラメータに拡張するための、10年にわたる壮大なエンジニアリングの戦いだったのだ。
いわゆる「スケーリング則」の現実:「脳」は変わらず、「身体」が容赦なく最適化された。
Transformerが「勝った」のは、GPU工場のフロア全体を一度に使える初めてのアーキテクチャだったからだ。
この記事を通じて、Transformerに対する解像度が少しでも上がれば嬉しい。読み終えた今、ぜひ「Transformerの根本的な弱点は何か?」を考えてみてほしい。
それでは、次の記事でまた会おう!
あとがき
この記事は以下のプロセスで制作した。
| 工程 | 担当 |
|---|---|
| 英語版の壁打ち・執筆補助 | Gemini 3.1 Pro(Web) |
| 日本語版の翻訳 | Claude Sonnet 4.6 High(Claude Code) |
| 読みやすさレビュー | 新井俊喜(営業) |
| 技術レビュー | 淺見将希(FDE) |
| ファクトチェック | 淺見将希(FDE)、Gemini 3.1 Pro(Web)、Claude Sonnet 4.6(Claude Code) |
Footnotes
Vaswani, A., et al. (2017). “Attention Is All You Need.” arXiv:1706.03762. ↩
Xiong, R., et al. (2020). “On Layer Normalization in the Transformer Architecture.” ICML 2020. arXiv:2002.04745. ↩
Zhang, B., & Sennrich, R. (2019). “Root Mean Square Layer Normalization.” NeurIPS 2019. arXiv:1910.07467. ↩
Su, J., et al. (2021). “RoFormer: Enhanced Transformer with Rotary Position Embedding.” arXiv:2104.09864. ↩
Peng, B., et al. (2023). “YaRN: Efficient Context Window Extension of Large Language Models.” arXiv:2309.00071. ↩
Shazeer, N. (2020). “GLU Variants Improve Transformer.” arXiv:2002.05202. ↩
Chowdhery, A., et al. (2022). “PaLM: Scaling Language Modeling with Pathways.” arXiv:2204.02311. ↩
Shazeer, N. (2019). “Fast Transformer Decoding: One Write-Head is All You Need.” arXiv:1911.02150. ↩
Ainslie, J., et al. (2023). “GQA: Training Generalized Multi-Query Transformer Models.” arXiv:2305.13245. ↩
Dao, T., et al. (2022). “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.” arXiv:2205.14135. ↩
Fedus, W., et al. (2022). “Switch Transformers: Scaling to Trillion Parameter Models.” JMLR. arXiv:2101.03961. ↩
Jiang, A. Q., et al. (2024). “Mixtral of Experts.” arXiv:2401.04088. ↩
Sebastian Raschka’s LLM Architecture Gallery: https://sebastianraschka.com/llm-architecture-gallery/ ↩