なぜON DELETE CASCADEで90%速くなるのか — PostgreSQLの内部構造から理解する
目次
はじめに
RECERQAでエンジニアをしている小野です。
弊社が提供する仕入消込エージェントには、CSVから仕入データを一括インポートする機能があります。この処理が本番環境で30,000件のデータ投入に1時間〜1時間半かかっており、ユーザー体験を大きく損なっていました。
この改善自体は別のメンバーが実装してくれたのですが、「なぜ遅かったのか」「なぜその変更で速くなるのか」を自分の言葉で説明できるレベルまで理解したいと考えました。今回はAIも補助的に使いつつ、PostgreSQLの内部構造まで掘り下げて腹落ちさせることを目的に取り組みました。
結果として、FK制約にON DELETE CASCADEを追加するだけで、削除処理単体では90.1%短縮、インポート全体では67.5%短縮が実現されていました。この記事では、その仕組みを紐解いた過程を紹介します。
先にお伝えしておきたいこと
ON DELETE CASCADEは強力ですが、万能ではありません。削除ロジックがDB内部に閉じるため、コードだけ見ても何が消えるか分からなくなります。知らずに親テーブルのDELETEを投げると、子テーブルのデータが意図せず連鎖的に消えてしまうリスクがあります。
元の実装でCASCADEが設定されていなかったのは、削除の順序や対象をコード上で明示的に管理し、意図しないデータ削除を防ぐためです。
論理削除であればデータの復旧が可能ですが、削除フラグを持つレコードが増え続けるため、別の運用課題が生じます。一方、物理削除+CASCADEはパフォーマンスに優れる反面、削除の取り消しが効きません。
今回CASCADEを採用できたのは、以下の前提があったからです。
- データの持ち方は今後再設計する前提のため、目の前の顧客のペインを解決する最適な手段だった
パフォーマンスと引き換えに、意図しない連鎖削除やデバッグの難しさというトレードオフがある点を踏まえたうえで、以降の内容をご覧ください。
処理の全体像
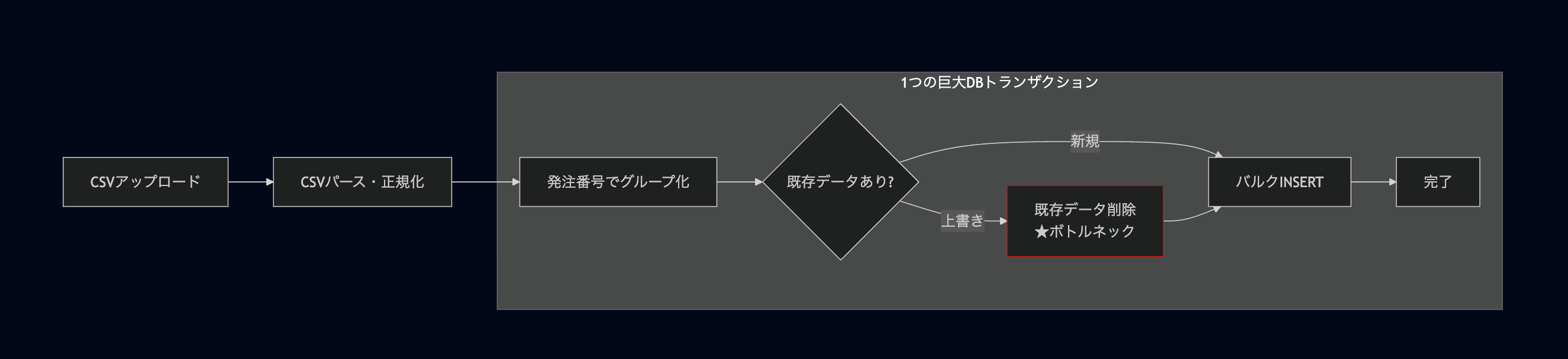
仕入データインポートは、CSVファイルを受け取り、発注・発注明細・入荷・入荷明細の4テーブルにデータを投入する機能です。既に同じ発注番号のデータが存在する場合は、既存データを削除してから再投入(overwrite)します。
この「削除→再投入」の流れが、1つの巨大なDBトランザクション内で実行されていました。
インポート処理のフロー
ボトルネックとなるテーブル構成
上書き時に削除が必要な4テーブルの関係です。purchasesを起点に、子テーブルが3つぶら下がっています。
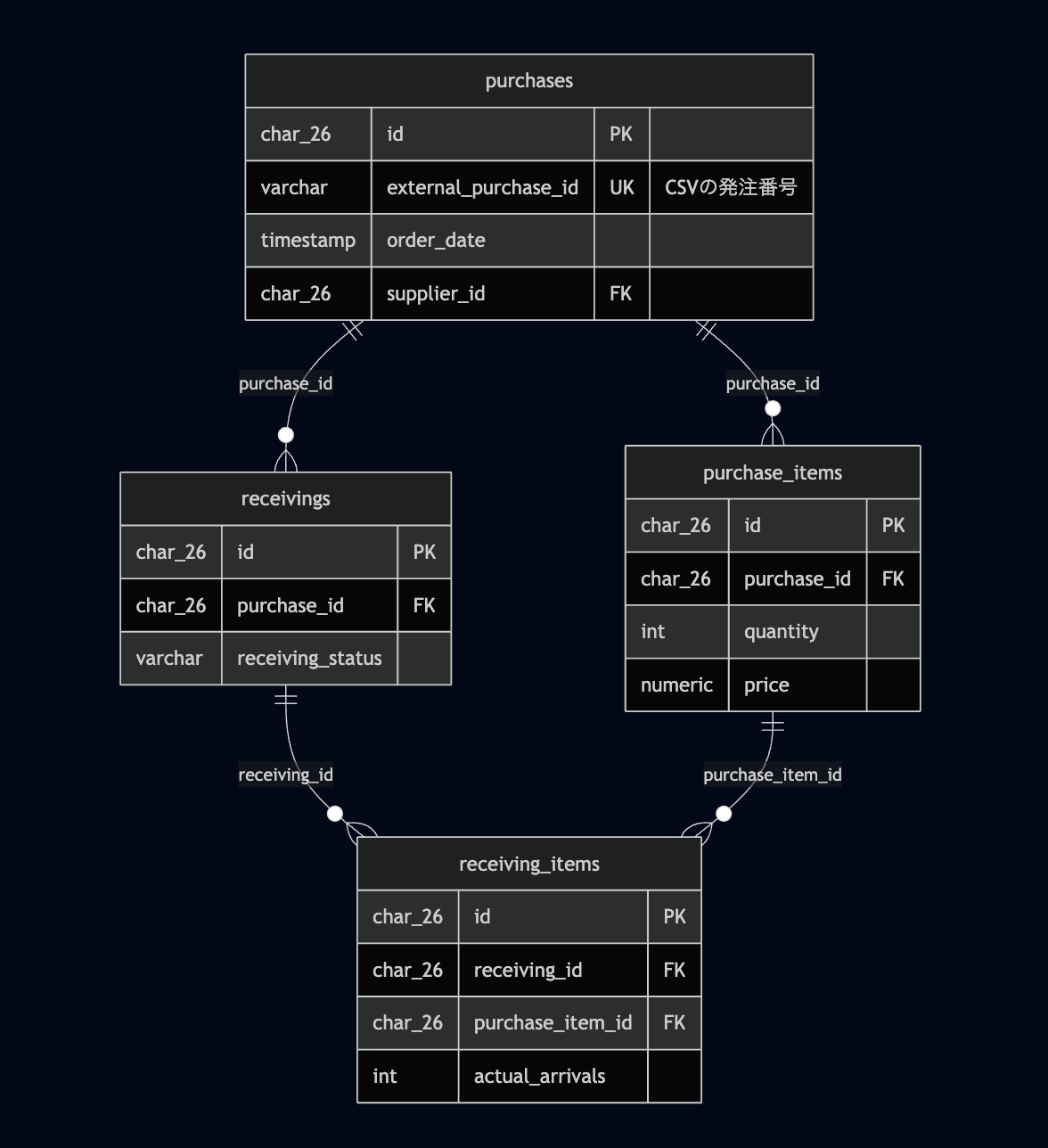
ON DELETE CASCADEが設定されていなかったため、purchasesを削除するには子テーブルから順に手動で削除する必要がありました。

実際のコードは以下のようになっていました。
func (r *PurchaseRepository) DeletePurchaseWithRelations(db *gorm.DB, purchaseID string) error { // 1. purchase_item_idを取得して receiving_items を削除 var purchaseItemIDs []string if err := db.Model(&orm.PurchaseItem{}). Where("purchase_id = ?", purchaseID). Pluck("id", &purchaseItemIDs).Error; err != nil { return errors.Wrap(err, "purchase_item IDsの取得に失敗しました") }
if len(purchaseItemIDs) > 0 { if err := db.Where("purchase_item_id IN ?", purchaseItemIDs). Delete(&orm.ReceivingItem{}).Error; err != nil { return errors.Wrap(err, "receiving_itemsの削除に失敗しました") } }
// 2. receivings を削除 if err := db.Where("purchase_id = ?", purchaseID). Delete(&orm.Receiving{}).Error; err != nil { return errors.Wrap(err, "receivingsの削除に失敗しました") }
// 3. purchase_items を削除 if err := db.Where("purchase_id = ?", purchaseID). Delete(&orm.PurchaseItem{}).Error; err != nil { return errors.Wrap(err, "purchase_itemsの削除に失敗しました") }
// 4. purchases を削除 if err := db.Where("id = ?", purchaseID). Delete(&orm.Purchase{}).Error; err != nil { return errors.Wrap(err, "purchasesの削除に失敗しました") }
return nil}この5クエリが10,000件バッチで繰り返されるため、本番環境では1時間〜1時間半もの処理時間がかかっていました。
なぜ遅かったのか
改善PRを見ると、変更内容はFK制約にON DELETE CASCADEを追加してアプリ側の手動DELETEを削除するというものでした。差分としてはシンプルです。
ただ「CASCADEを付けたから速くなった」で理解を終わらせたくなかったので、そもそもなぜ元の実装が遅かったのかを掘り下げてみました。
ON DELETE CASCADEがなかった
改善前のコードでは、FK制約にON DELETE CASCADEが設定されておらず、アプリ側で子テーブルから順に手動でDELETEを発行していました。
ここまでは改善PRの差分からすぐ読み取れます。疑問に感じたのは計測値の方です。3,000件の2回目は0.18秒で終わるのに、30,000件の2回目は62.7秒。件数が10倍なら時間も10倍になりそうなものですが、実際には約350倍でした。手動DELETEが多いだけなら、こんな非線形な悪化にはならないはずです。
MVCC と dead tuple
ここからPostgreSQLの内部構造を調べ始めました。まず分かったのが、PostgreSQLではDELETEを実行しても行が物理的に削除されないということです。
PostgreSQLはMVCC(Multi-Version Concurrency Control) という仕組みで同時実行制御を行っています。すべての行には、ユーザーからは見えない2つのシステムカラムがあります。
| カラム | 意味 | セットされるタイミング |
|---|---|---|
xmin | この行をINSERTしたトランザクションID | INSERT時 |
xmax | この行をDELETEしたトランザクションID | DELETE時(0 = 未削除) |
行の実際のデータ: id | name | price | xmin | xmax -----+--------+-------+------+------ aaa | 商品A | 1000 | 100 | 0 ← 作成済み、まだ削除されていない bbb | 商品B | 2000 | 100 | 150 ← #150で削除された(でもまだページ上にいる)DELETEは行のxmaxにトランザクションIDをセットするだけ。物理的にはページ上に残り続けます。これがdead tupleです。
なぜわざわざ残すのか。進行中のトランザクションが読んでいる途中で行が消えたら、データの不整合が起きるからです。MVCCは「削除しても消さない」ことで、他のトランザクションに影響を与えずに削除を実現しています。
物理的な掃除はVACUUMというプロセスが後から担当します。ただしここに重要な制約がありました。進行中のトランザクションが参照している可能性がある行は消せないのです。
巨大トランザクションの悪影響
ここまで調べて、ようやく350倍の悪化の構造が見えてきました。インポート処理全体が1つの巨大なトランザクションで実行されていたのです。
トランザクション#200 の中で起きていること:
[DELETEフェーズ] receiving_items 10,000件DELETE → dead tupleが10,000個蓄積 receivings 10,000件DELETE → dead tupleがさらに蓄積 purchase_items 10,000件DELETE → さらに蓄積... purchases 10,000件DELETE → さらに蓄積... (これが4バッチ繰り返される)
[INSERTフェーズ] → dead tupleだらけのテーブルに新しい行を追加 → 空きページを探すためにdead tupleのページも読む
トランザクション進行中 → VACUUMが動いても、このトランザクションが生んだdead tupleは回収できない → dead tupleは処理が終わるまで蓄積し続けるDELETEが進むほどdead tupleが増え、後続のDELETEやINSERTのスキャン対象行数がどんどん膨らんでいきます。VACUUMは動作しますが、進行中のトランザクションから見えるdead tupleは回収できないため、掃除が追いつきません。
WALも膨れ上がる
dead tupleに加えて、WAL(Write-Ahead Log) も問題になっていました。PostgreSQLはテーブルを変更する前にまずログファイルへ書き込みます。クラッシュしてもここから復元できるようにするためです。
数件のINSERT/UPDATE程度ならWALは小さく収まりますが、更新件数や行サイズが増えると一気に膨れ上がります。
通常のトランザクション: WAL: 100レコード → COMMIT → fsync(数KB) → 即完了
今回のトランザクション(30,000件 overwrite): DELETE ~100,000行 → WALレコード ~100,000個 INSERT ~100,000行 → WALレコード ~100,000個 合計: WAL ~200,000レコード → 数百MBWALバッファはデフォルト16MBなので、何度も溢れてそのたびにディスクI/Oが走ります。COMMIT時にも数百MB分のfsyncが必要です。
件数が増えると非線形に悪化する理由
改めて計測値を見ると、この非線形な悪化の理由が腑に落ちました。
| 件数 | 削除処理の時間 | 倍率 |
|---|---|---|
| 3,000件(2回目) | 0.18秒 | 1x |
| 30,000件(2回目) | 62.7秒 | 約350x |
| 要因 | 影響 |
|---|---|
| dead tupleの蓄積 | 後続のDELETE/INSERTがスキャンする行数が増え続ける |
| VACUUMが回収できない | 進行中トランザクションに可視なdead tupleは掃除できない |
| WALの肥大化 | バッファ溢れによるディスクI/O + COMMIT時の大量fsync |
| 全てが1トランザクション | 上記3つが処理全体を通じて蓄積し続ける |
3,000件ならdead tupleやWALは小さく収まります。しかし30,000件になると雪だるま式に効いてきます。「クエリが多いから遅い」のではなく、「巨大トランザクション内でdead tupleとWALが蓄積し続けるから遅い」というのが正体でした。
ON DELETE CASCADEで何が変わったのか
原因が分かったところで、改善内容を見ていきます。FK制約にON DELETE CASCADEを追加し、アプリ側の手動DELETE(5クエリ)を削除。purchasesのDELETEを1回発行するだけで、子テーブルはPostgreSQLが自動で消してくれるようになりました。
ただ「5クエリが1クエリになったから速い」では、先ほどと同じで表面的な理解で終わってしまいます。CASCADEの内部で何が起きているのかを調べました。
CASCADEの中身
ON DELETE CASCADEの実体は、PostgreSQLが内部的に生成するAFTER DELETEトリガーでした。purchasesの行が削除されるたびにトリガーが発火し、子テーブルの該当行を自動削除します。子テーブルにもCASCADE制約があれば再帰的に発火します。
DELETE FROM purchases WHERE id IN ('aaa', 'bbb', ...)
エグゼキュータの動き: 'aaa' を削除 → xmaxセット → WAL記録 → CASCADEトリガー発火 → purchase_items: purchase_id='aaa' をインデックスで引く → 削除 → receiving_items: purchase_item_id をインデックスで引く → 削除 → receivings: purchase_id='aaa' をインデックスで引く → 削除 'bbb' を削除 → 同様に連鎖 ...1回のSQL実行の中で、親→子→孫の削除が連鎖的に処理されます。
パーサーとプランナーをスキップする
このように処理していることを知りませんでした。PostgreSQLがSQL文を実行するときは通常3段階を経ます。
- パーサー — SQL文字列を構文木に変換する
- プランナー — 構文木から最適な実行計画を生成する(Seq Scan / Index Scanの比較、IN句の展開など)
- エグゼキュータ — 実行計画に従って実際にデータを読み書きする
手動DELETEでは5つのSQL文それぞれでこの3段階すべてが走ります。とくにIN句10,000個の展開とプラン最適化は重い処理です。
一方、CASCADEによる子テーブルの削除はSQL文として実行されません。PostgreSQLの内部C関数がエグゼキュータを直接呼び出します。つまりパーサーとプランナーを完全にスキップしています。
プランナー についてはまた別の機会に深掘りしてみたいです。
IN句10,000個 vs 1値のインデックスルックアップ
検索の仕方も大きく違いました。手動DELETEではWHERE purchase_item_id IN (10,000個)のように大量の値を一括で照合しています。
CASCADEでは、親1行の削除ごとにWHERE purchase_id = 'aaa'と1つの値でインデックス(B-Tree)を引きます。B-Treeの探索はツリーの深さ分(3〜4ページ)を読むだけで該当行に到達するので、各回の処理が極めて軽いです。
これらの違いを整理するとこうなります。
| 観点 | 手動DELETE | CASCADE |
|---|---|---|
| パーサー・プランナー | 5回/バッチ | 1回(子はスキップ) |
| アプリ↔DB通信 | 5往復/バッチ | 1往復/バッチ |
| 子テーブルの検索 | IN句10,000個の照合 | 1値のインデックスルックアップ |
| 共有バッファ | テーブルごとに切り替え | 関連データがまとまって処理されキャッシュ効率が向上 |
計測結果
ローカル環境で30,000件の再インポートを計測した結果です。
改善前
| ステップ | 30,000件(初回) | 30,000件(2回目) |
|---|---|---|
| CSVパース | 0.09秒 | 0.09秒 |
| 前処理(既存データ削除) | 0.27秒 | 63.2秒 |
| └ BulkDeletePurchaseWithRelations | - | 62.7秒 |
| バルクINSERT | 17.5秒 | 17.9秒 |
| クリーンアップ | 0.03秒 | 0.03秒 |
| 合計 | 18.1秒 | 81.8秒 |
初回インポートでは削除対象がないため高速ですが、2回目(overwrite)で削除処理がボトルネックとなり、全体の**77%**を占めています。
ON DELETE CASCADE 適用後
| ステップ | 改善前 | CASCADE適用後 | 改善率 |
|---|---|---|---|
| CSVパース | 0.09秒 | 0.09秒 | - |
| 前処理(既存データ削除) | 63.2秒 | 6.6秒 | 89.5%短縮 |
| └ BulkDeletePurchaseWithRelations | 62.7秒 | 6.2秒 | 90.1%短縮 |
| バルクINSERT | 17.9秒 | ~19.6秒 | - |
| クリーンアップ | 0.03秒 | 0.07秒 | - |
| 合計 | 81.8秒 | 26.6秒 | 67.5%短縮 |
ボトルネックだった削除処理は62.7秒→6.2秒と90%短縮されました。全体では81.8秒→26.6秒で67.5%の短縮です。
本番環境で1時間〜1時間半かかっていた処理も、データ分布やI/O特性の差はありますが、同程度の改善が期待できそうです。
AIを活用した調査プロセスの振り返り
今まではAIに任せてなんとなく改善していた箇所を、今回は根っこの部分まで理解することを意識して調べました。
今の時代、AIに「原因調査して」と言えば、それなりの精度でボトルネックを見つけて修正案まで出してくれます。ただ、それが本当に正しいのか、なぜその変更で改善するのかまでは別です。
今回は「CASCADEを付ければ速い」で終わらせず、なぜ削除処理が詰まっていたのか、なぜCASCADEで改善するのかまで説明できるところまで掘れたのが収穫でした。
まとめ
FK制約にON DELETE CASCADEを追加するだけで、ボトルネックだった削除処理を90%短縮できました。
- 手動DELETEの5クエリ → CASCADEによる1クエリに削減
- ローカル計測で全体81.8秒→26.6秒(67.5%短縮)
- 本番環境で1時間〜1時間半かかっていた処理の大幅な改善
変更量は小さくても、PostgreSQLの内部構造(MVCC、dead tuple、WAL)を理解すれば、なぜ効果があるのか説明できます。AIに修正案を出してもらえる時代だからこそ、「なぜ直るのか」を理解する価値はむしろ大きいと感じました。
今ならAIに聞くと内部構造まで理解することが比較的容易になっています。5年、10年前はこうしたところを自力で調べ切るのが当たり前だったはずで、経験を積んだエンジニアが強い理由にも納得しました。