Google TimesFM でバイク輸入商社の需要予測を検証した話
目次
はじめに
こんにちは。リチェルカでFDEをしている淺見です。
お客様の受注・在庫データに日々触れる中で、「このデータで需要予測はどこまでできるのか」が気になっていました。
精度の高い予測ができればお客様への価値提供につながりますし、それをプロダクトとしてどう届けるかも考えたい。そこで今回、うえさか貿易というバイク輸入商社の販売実績を使って検証するに至りました。
入社してから今までPdMとして業務量が多く、なかなかこうした検証に手を出せていませんでした。会社と自分の両方が一歩成長したと感じています。
うえさか貿易とリチェルカ
少し背景を説明します。リチェルカの代表・梅田はバイクが趣味で、イタリア製バイクパーツの輸入商社であるうえさか貿易を事業承継しています。私たちはうえさか貿易の実務——海外メーカーへの発注、在庫管理、顧客への納品——にも関わっているので、商社・卸売業を営む人たちが何に困っているかを肌感覚で知っています。
「次の四半期、どの部品をいくつ仕入れればいいのか」。発注リードタイムが長い海外仕入れでは、この判断が在庫コストと欠品リスクに直結します。うえさか貿易でも毎回悩むポイントで、ここに需要予測が使えたら面白いなと思っていました。
そこで、オープンソースですぐに検証できるtimesfmで需要予測を試すことにしました。TimesFMはファインチューニングなしにゼロショットで予測できます。この手軽さが検証のハードルを下げてくれる点に魅力を感じました。ERPに蓄積された時系列を入力したとき、どこまで当たるのか個人的な興味から始めた検証です。
本記事では、その結果を正規化・匿名化した形で共有します。
データ利用と公開範囲
本検証では、社内で検証目的に参照した受注データを集計し、公開にあたっては売上金額・商品名・取引先名などの識別情報を除外したうえで、正規化した集計値と図表のみを掲載しています。個別の受注や顧客を復元できる情報は、本文と図版のいずれにも含めていません。
TimesFM 2.5とは
TimesFMはGoogleが開発した時系列予測の基盤モデル(Foundation Model)です。2024年5月にv1.0が公開され、その後v2.0(2025年2月)を経て、本検証で使用した v2.5(200Mパラメータ)が最新版です。
主な特徴は以下の通りです。
- ゼロショット予測: ファインチューニング不要。データを入れるだけで予測が出る
- 分位点予測: 点予測に加え、10%〜90%分位点レンジを同時に出力
- 長いコンテキスト: 最大16,384トークンの入力に対応
- PyTorchネイティブ:
google/timesfm-2.5-200m-pytorchとしてHugging Face上で公開
import timesfm
model = timesfm.TimesFM_2p5_200M_torch.from_pretrained( "google/timesfm-2.5-200m-pytorch")model.compile( timesfm.ForecastConfig( max_context=2048, max_horizon=13, normalize_inputs=True, use_continuous_quantile_head=True, force_flip_invariance=True, infer_is_positive=True, ))
# 予測実行(入力は1次元の時系列配列)point_forecast, quantile_forecast = model.forecast( horizon=13, inputs=[weekly_sales])Claude Codeを使って数行のスクリプトを作って予測してもらいました。便利。
検証設計
データ
ERPシステムに蓄積された、あるテナントの受注データを使用しました。
| 項目 | 内容 |
|---|---|
| 期間 | 2022年6月 〜 2025年12月(約3.5年) |
| 集計単位 | 週次(全体売上)/ 月次(商品別) |
| 予測対象 | 2026年2月〜3月 |
| 商品数 | 45商品 |
検証の構成
検証は2段階で行いました。
- 全体売上の予測: 全商品の売上合計を週次で予測し、データ量による精度変化を確認
- 商品別の予測: 45商品それぞれの月次注文数量を予測し、商品特性による精度差を分析
精度指標
- 合計誤差率:
|予測合計 - 実績合計| / 実績合計 × 100 - MAPE(平均絶対パーセント誤差): 各期間の誤差率の平均
- 予測レンジ被覆率: 実績が10%〜90%分位点レンジに収まった割合
全体売上の予測検証
まず、全商品の売上合計を週次で予測しました。ここで重要な発見がありました。入力履歴の長さが精度を大きく左右するということです。
v1: 直近1年分のみ → 誤差54%
最初の実験では、2025年1年分のデータ(53週)のみをTimesFMに入力しました。結果は合計誤差率54.0%、MAPE 78.6%と、実用には程遠い精度でした。
v2: 全履歴データ → 誤差29%
次に、利用可能な全履歴(2022年6月〜2025年12月、185週)を入力したところ、合計誤差率は28.9%、MAPEは47.3%まで改善しました。
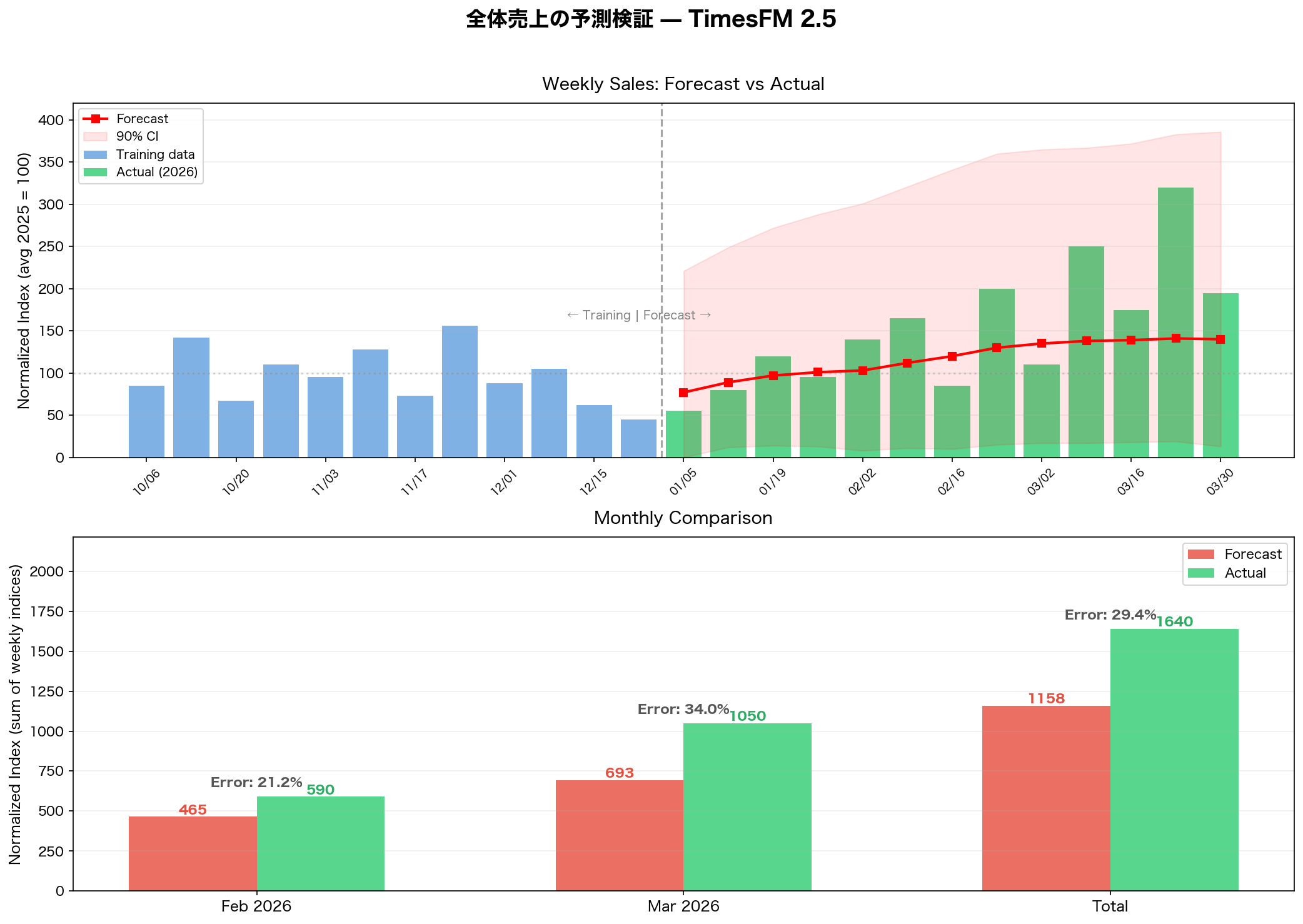
上のグラフでは、Y軸を「正規化指数」(2025年の平均週次売上=100)で表示しています。予測期間のグリーンの棒(実績)に対し、赤い折れ線(予測)は全体的に低めに推移しており、モデルは一貫して過小評価でした。
特に3月には、実績の伸びが大きい週もありました。モデルはその動きを捉えきれていません。月別で見ると、2月の誤差は約21%で参考利用できる水準です。一方3月は約34%に悪化しました。2ヶ月合計で約29%という数字は、月ごとのばらつきを均した結果です。
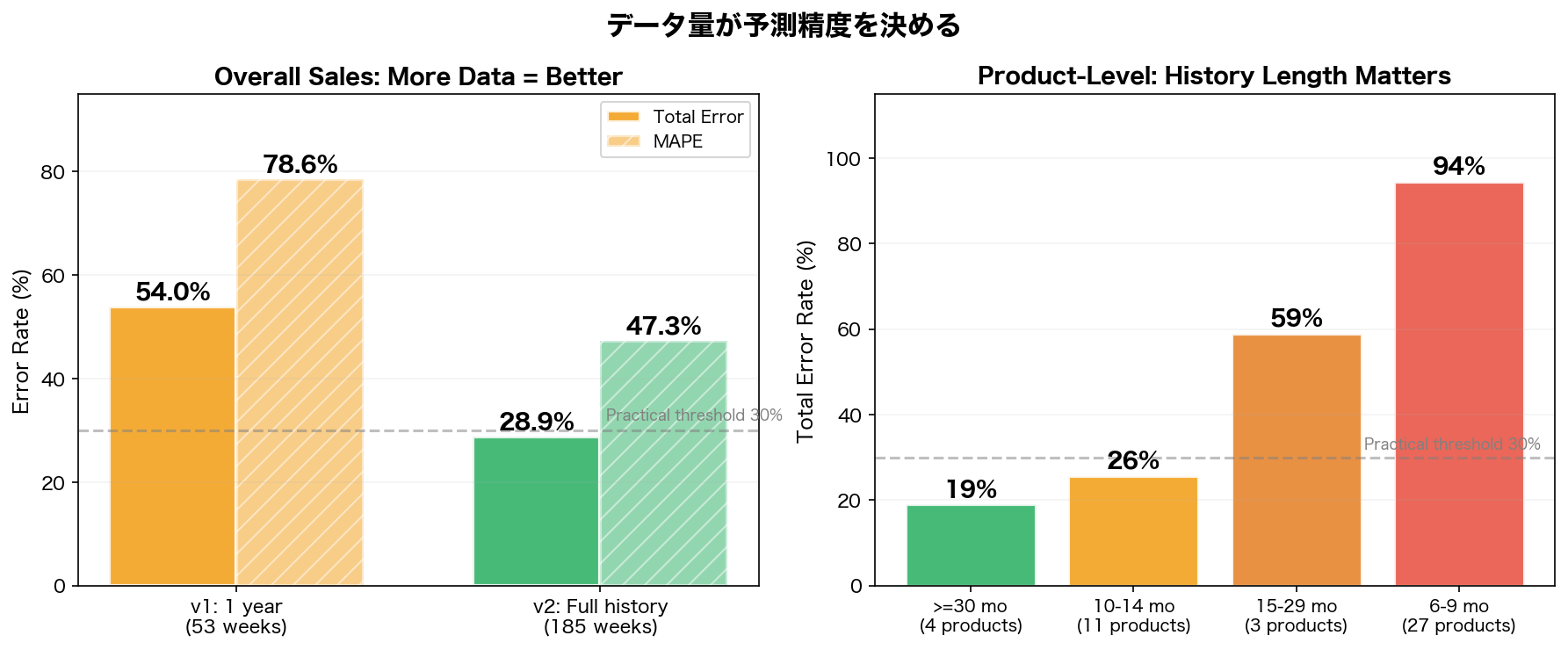
今回の条件では、入力履歴を約3.5倍に伸ばすと、合計誤差は54%→29%とほぼ半減しました。TimesFMのような基盤モデルでは、与える履歴の長さが予測精度に強く効くことが分かります。
補足: 全体注文数では合計誤差3.2%
売上と同じ全履歴runを対象にしました。まず、forecast_v2_result.csv から該当期間の predicted_orders を抽出しました。次に、forecast_v2.py と同じ月次ルールで集計しました。その結果、注文件数ベースの予測値は実績と近い水準になりました。実績件数には、比較スクリプトが月次比較用に集計した値を使っています。
表1. 全体注文数 × 全履歴の月別集計
| 月 | 対象週 (week_start) | 予測件数 | 実績件数 | 月次差分 |
|---|---|---|---|---|
| 2026年2月 | 02-02, 02-09, 02-16, 02-23 | 42.3 | 41 | +1.3 |
| 2026年3月 | 03-02, 03-09, 03-16, 03-23, 03-30 | 59.3 | 64 | -4.7 |
| 合計 | 9週 | 101.6 | 105 | -3.4 |
表1の通り、2ヶ月合計の誤差率は |101.6 - 105| / 105 × 100 = 3.2% です。月別では2月が3.2%、3月が7.4%で、2ヶ月合計では過大予測と過小予測が一部相殺されています。したがって、この指標は「全体の注文ボリュームは概ね捉えた」ことを示しますが、前節で見た商品別精度の問題を打ち消すものではありません。
商品別の予測検証
次に、商品ごとの月次注文数量を予測しました。ここで見えてきたのは、全体売上の精度と商品別の精度はまったく別物だということです。
高頻度商品: 精度良好
月平均5個以上の注文がある6商品については、2ヶ月合計の予測誤差はわずか 8.8% でした。少なくとも今回の対象では、比較的良好な精度です。
低頻度商品: 予測が崩壊
一方、月平均1〜2個しか注文がない26商品では、誤差率は 93.4% に達しました。予測合計81個に対し実績は159個であり、多くの商品では予測値がほぼゼロに潰れています。結果として、「注文が来ない」とみなしたような予測になっています。
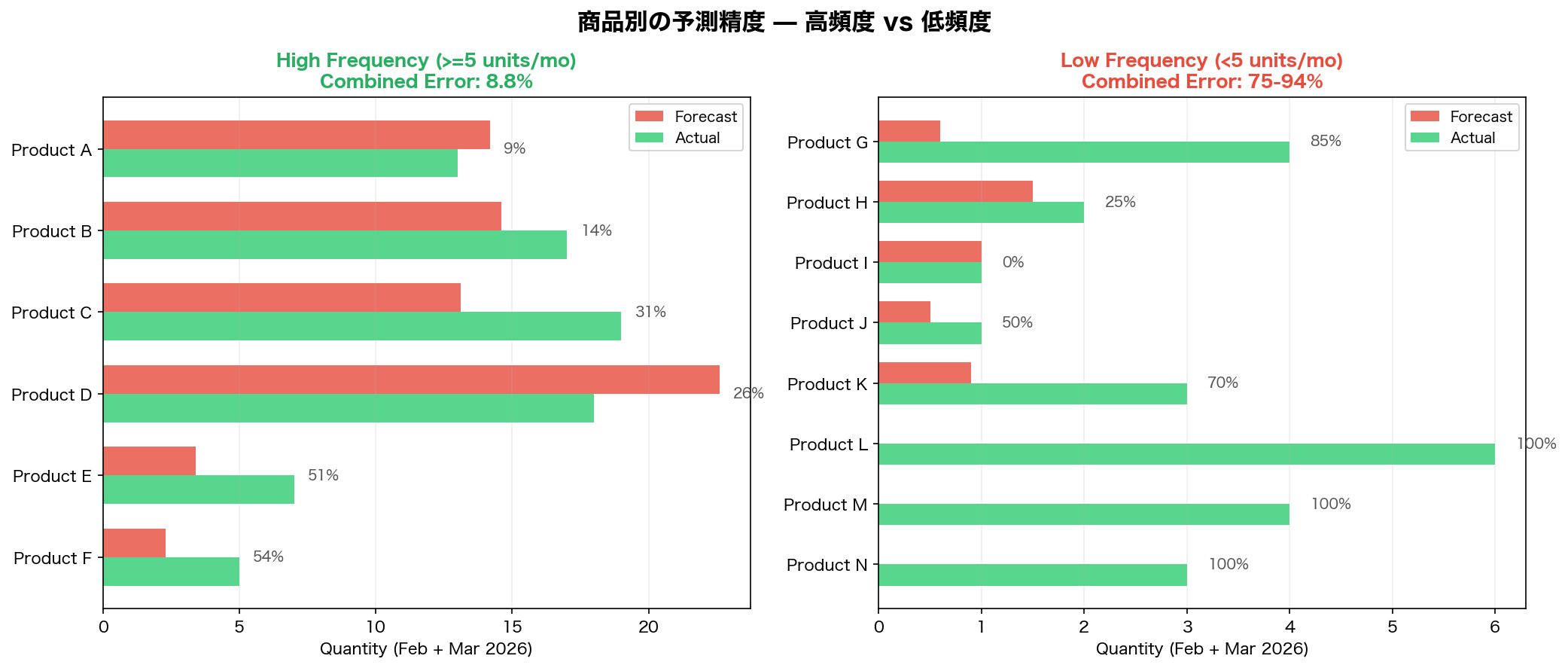
左のグラフ(高頻度商品)では赤い予測バーと緑の実績バーがほぼ揃っています。右のグラフ(低頻度商品)では、予測バーがほとんど見えないほど小さく、実績との乖離が顕著です。
これは「間欠需要(intermittent demand)」と呼ばれる問題で、ゼロが多い時系列では予測値がゼロ近傍に寄りやすくなります。TimesFMに限らず、多くの時系列モデルが抱える構造的な弱点です。
精度はデータ量に依存する
商品別の精度差の要因を切り分けるため、「履歴月数」と「月平均の注文数量」をそれぞれ誤差率と比較しました。
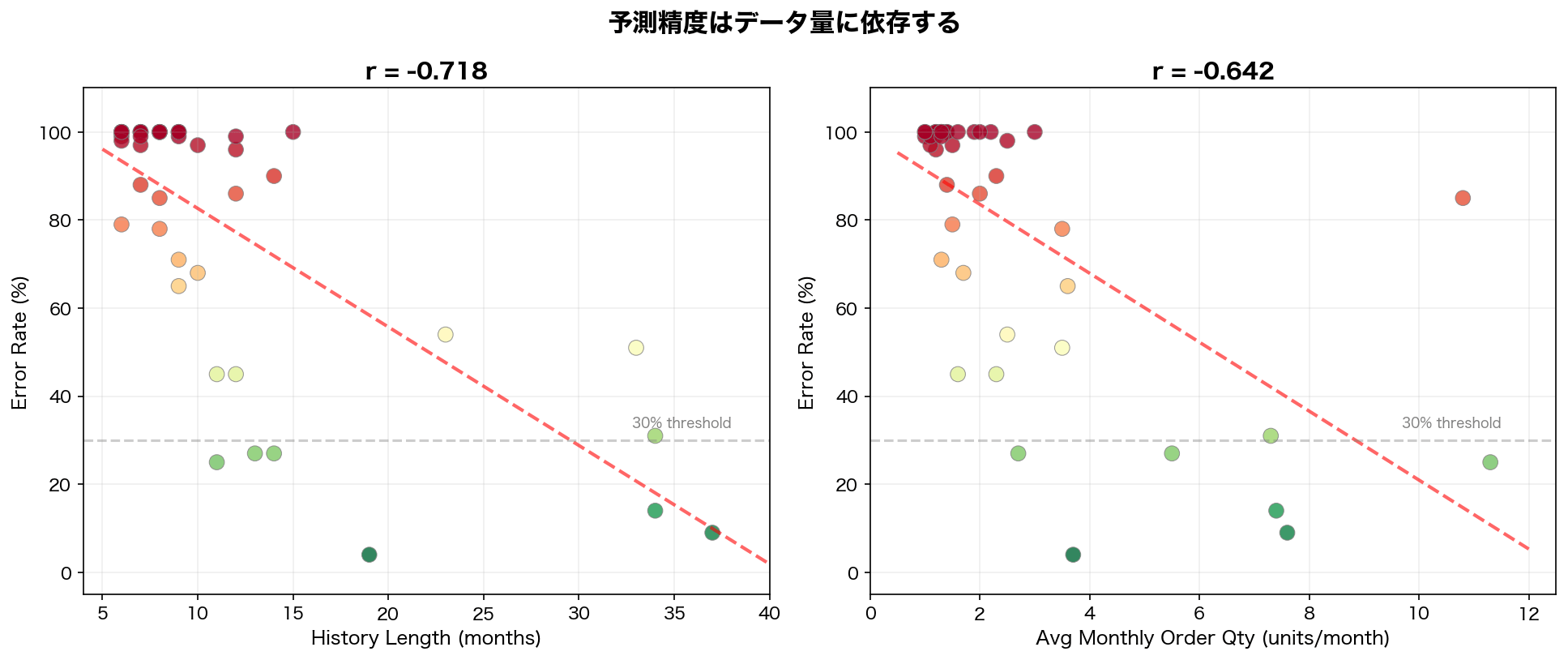
結果は明確でした。
- 履歴月数vs誤差率: 相関係数r = -0.718(強い負の相関)
- 月平均注文数vs誤差率: 相関係数r = -0.642(やや強い負の相関)
今回の検証では、30ヶ月以上の履歴がある商品の誤差率は平均19%、6〜9ヶ月しかない商品は95%でした。同様に、月5個以上の注文がある商品は8.8%、月1〜2個の商品は93%です。
つまり、今回の精度は「モデル名」よりも「入力履歴の長さ」と「注文頻度」に強く左右されていたということです。履歴が十分に長く、かつ注文頻度が高い系列では精度が改善し、そうでない系列では基盤モデルでも限界がありました。
落とし穴: 合計誤差のミスリード
本検証で最も重要な発見は、全体レベルの精度が商品レベルの精度を保証しないということです。
全体売上の合計誤差率は28.9%で、一見すると使えそうに見えます。しかし、これは高頻度商品の正の誤差と低頻度商品の負の誤差が相殺された結果に過ぎません。
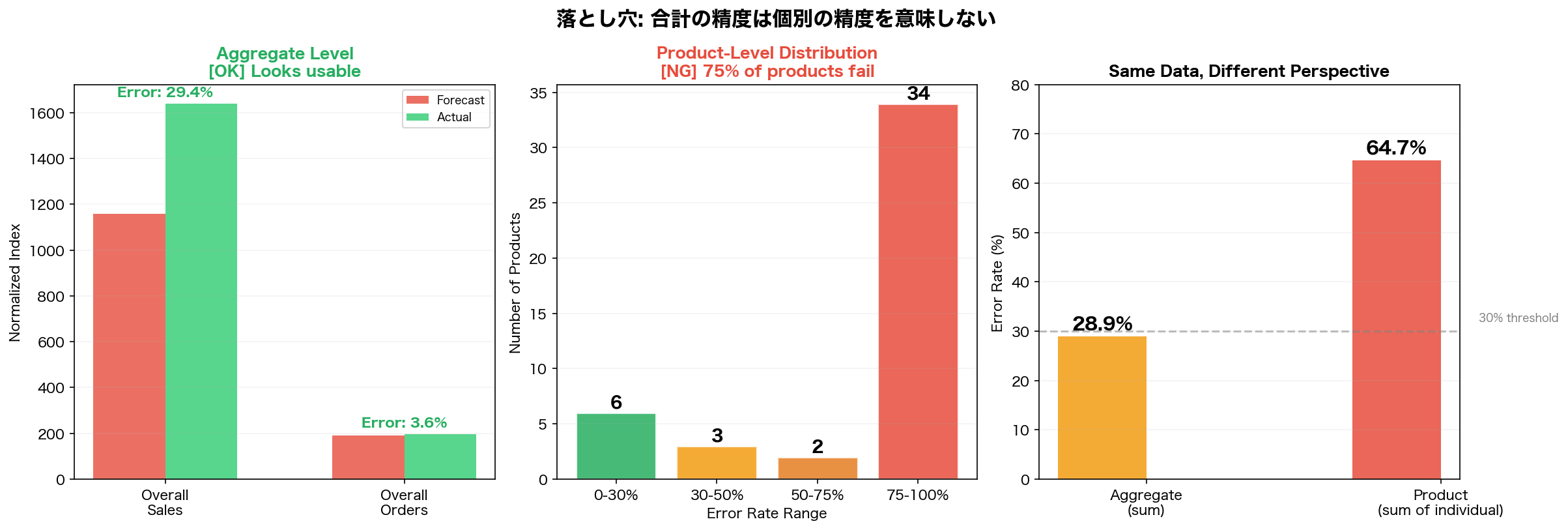
中央のグラフを見てください。45商品のうち、誤差率30%以内に収まっているのはわずか6商品。全体の75%にあたる34商品が誤差75%以上です。
これは在庫管理の文脈では致命的です。「全社の売上予測」は経営レベルの参考にはなりますが、「商品Aを何個仕入れるか」という実務判断には使えません。予測モデルを導入する際は、どの粒度で使うのかを必ず明確にしてから精度を評価すべきです。
検証の制約
ここまでの結果は興味深い一方で、解釈にはいくつか制約があります。
- 本検証は単一テナントの単一期間(2026年2月〜3月)に対する事後検証であり、他社データや他期間にそのまま一般化できるわけではない。
- TimesFMはゼロショット推論で使っており、追加学習や業務固有の特徴量は入れていない。したがって、ここで見ているのは「そのまま使ったときの初期性能」である。
- 合計誤差が低く見えるケースでも、商品別の発注判断に必要な精度が出ているとは限らない。評価粒度を変えると結論も変わる。
結論と今後
TimesFM 2.5は限定条件では検討余地がある

| 条件 | 誤差率 | 判定 |
|---|---|---|
| 全体売上 × 全履歴(185週) | 29% | △ 参考利用 |
| 全体注文数 × 全履歴 | 3.2% | ○ 総量把握 |
| 高頻度商品 × 30ヶ月以上 | 19% | △ 条件付き |
| 高頻度商品 × 月5個以上 | 8.8% | ○ 有望 |
| 中頻度商品 × 月2〜4個 | 70% | × 不十分 |
| 低頻度商品 × 月1〜2個 | 93% | × 不適 |
本検証の範囲では、十分な入力履歴と注文頻度がある条件で、集計レベルの予測は参考値になり得ます。 特に高頻度商品の予測や全体トレンドの把握には検討余地があります。一方で、全体注文数ベースの3.2%は月別の誤差が一部相殺された結果でもあるため、商品別の発注判断とは分けて読む必要があります。
一方で、ERPデータの大半を占める低頻度商品には対応できません。これはTimesFMの問題というよりも、疎な時系列に対する基盤モデル全般の構造的限界です。
今後の方向性
- 間欠需要への対応: Croston法やTSB法など、間欠需要に特化した手法との組み合わせを検討
- 外部情報の活用: カレンダー情報、イベント・キャンペーン情報などの共変量を加えることで精度向上を狙う
- ハイブリッドアプローチ: 高頻度商品はTimesFM、低頻度商品は別手法、という使い分けが現実的
- データ蓄積の重要性: 今回の検証では、長い履歴を持つ商品群ほど精度改善の傾向が見られた。ERPベンダーとして「データを貯め続ける」こと自体が価値になる
今後は、こうした条件差を前提に、どの粒度なら業務に載せられるかを見極めながら検証を深めていくつもりです。AIエージェントの一部にこのモデルを活用できる余地があるかも、引き続き検討していきます。
最後まで読んでいただき、ありがとうございました。
本記事で使用したデータはすべて正規化・匿名化しています。実際の売上金額や商品名は含まれていません。
検証に使用したモデル: google/timesfm-2.5-200m-pytorch